파이썬 과제! 원하는 사이트 내용을 크롤링한 다음 원하는 형식으로 저장하시오
나는 멜론 차트의 일간 차트 중 국내종합을 매일 수집하여 엑셀 파일로 저장하도록 만들었다. 전체 코드는 맨 아래에 있음!!
www.melon.com/robots.txt 에 들어가서 확인해보면 거의 모든 것을 허락한다는 것을 알 수 있다. 먼저 사용할 url은 아래와 같다.
url : https://www.melon.com/chart/day/index.htm
일간차트의 경우 장르종합, 국내종합, 해외종합 그리고 각각의 장르별로 나눠져 있다.
나는 그 중에서 국내종합과 해외종합을 클릭한 후에 1위부터 100위까지를 가져와서 엑셀에 각각 다른 시트로 저장해보기로 했다.
먼저 필요한 내용부터 import하자!
|
1
2
3
4
5
6
7
|
# -*- coding:utf-8 -*-
from selenium import webdriver
from bs4 import BeautifulSoup
import time
import pandas as pd
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
|
cs |
그리고 selenium과 크롬 드라이버로 멜론 창을 켠 후 국내종합을 클릭해보자.
|
1
2
3
4
5
6
7
8
9
10
11
|
url = 'https://www.melon.com/chart/day/index.htm'
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(3)
driver.get(url)
time.sleep(1)
# 국내 차트 클릭
driver.find_element_by_xpath('/html/body/div/div[3]/div/div/div[2]/dl/dd[1]/ul/li[2]/a').click()
time.sleep(2)
|
cs |
국내종합을 클릭하기 위해 element를 가져와야 하는데 다양한 방법이 있겠으나 나는 Xpath로 가져왔다. 원하는 xpath를 얻는 법은 아래 사진을 보면 나온다.
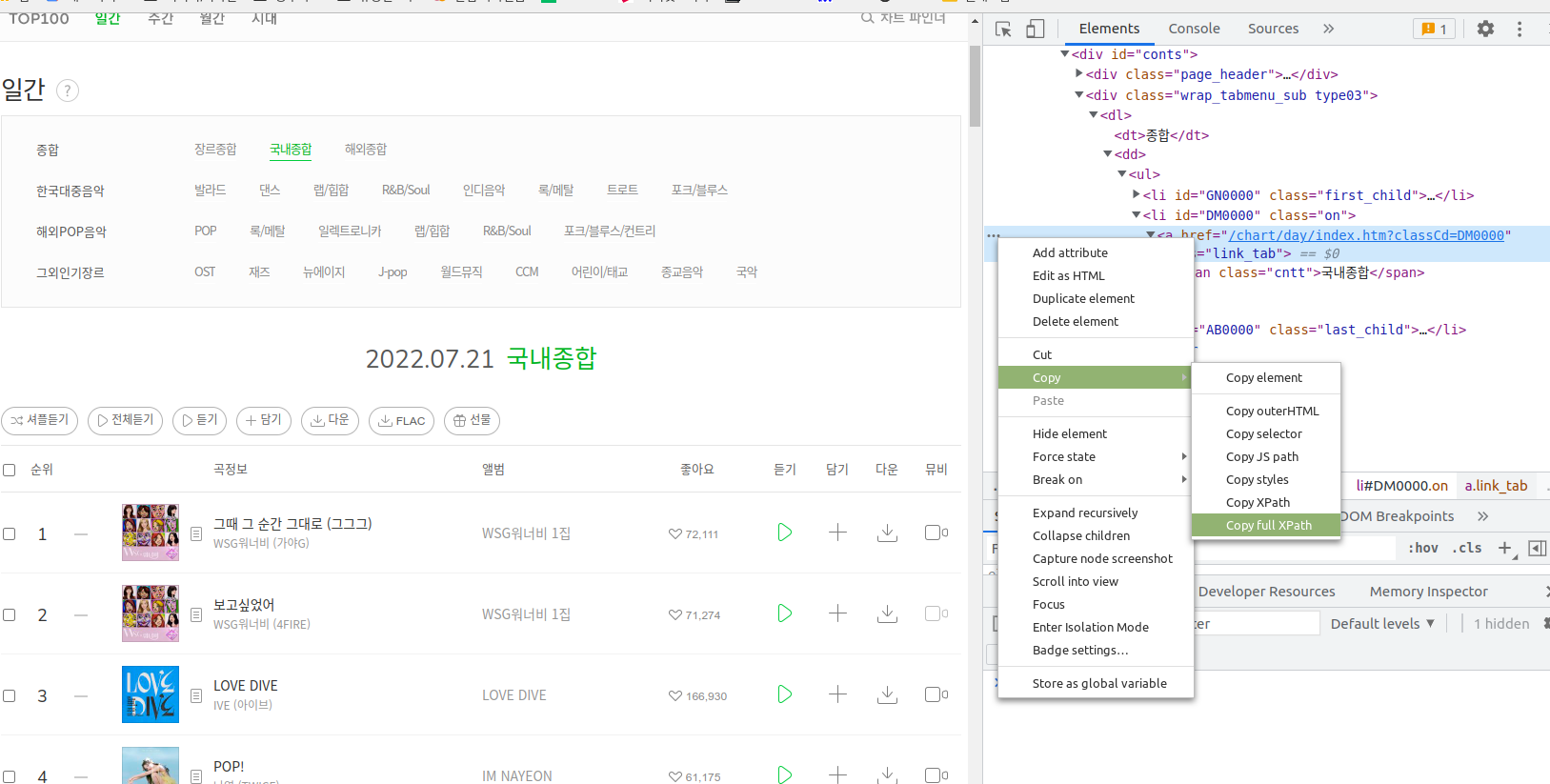
위의 사진처럼 내가 사용하고 싶은 부분을 선택한 후 왼쪽의 ...을 누른 후에 Copy에서 Copy full Xpath를 누르면 된다. 저기까지 쓴 다음 실행하면 멜론 일간 차트 창이 켜지고 '국내종합'이 클릭된다. 그럼 이제 차트를 가져오자!
내가 가지고 오려는 차트 정보는 순위, 노래 제목, 가수, 앨범, 앨범 사진 주소, 좋아요 숫자이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
soup = BeautifulSoup(driver.page_source, 'html.parser')
table = soup.select_one('.service_list_song table tbody')
trs = table.find_all('tr')
song_list = []
for tr in trs:
temp = {}
temp['rank'] = tr.select_one('.rank').text
temp['title'] = tr.select_one('.wrap_song_info').select_one('div.ellipsis.rank01 span a').text
temp['artist'] = tr.select_one('.wrap_song_info').select_one('div.ellipsis.rank02 span a').text
temp['album'] = tr.select_one('td:nth-child(7) > div > div > div > a').text
temp['album_img'] = tr.select_one('td:nth-child(4) > div > a > img').get('src')
temp['likes'] = tr.select_one('.button_etc.like .cnt').text.replace('\n총건수\n', '')
song_list.append(temp)
|
cs |
위와 같이 BeautifulSoup를 이용해서 필요한 데이터를 가지고 왔다. 먼저 테이블 속의 tbody를 얻은 다음 그 안에 있는 tr들을 trs에 넣어 주었다. 그런 다음 for문을 돌려 각각의 정보를 얻어낸 후 song_list에 담아 주었다.
select_one에 들어갈 정보는 위에서 Copy full Xpath을 가져온 것 처럼 Copy selector로 정보를 유추한 다음 가져오면 된다.
그리고 각각 얻은 정보들을 먼저 temp에 {}형식으로 넣은 후 song_list에 담아주었기 때문에 나중에 엑셀에 저장할 때 rank, title 등이 맨 위의 열에 들어가도록 하였다.
여기까지 만든 내용을
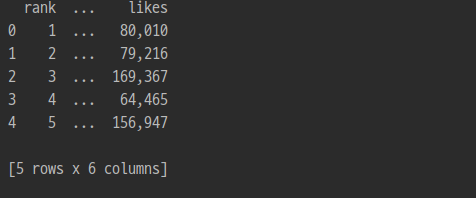
print(song_list)로 실행하면 콘솔에 아래와 같이 뜬다.

제대로 잘 데리고 온다는 것을 알았으니 이제 엑셀에 넣기 위해 처리해보자.
|
1
2
3
4
5
6
7
8
|
# 엑셀에 넣기 위해 처리
ko_chart = pd.DataFrame(song_list)
print(ko_chart.head())
# 저장
writer = pd.ExcelWriter('melonchart.xlsx', engine='openpyxl')
ko_chart.to_excel(writer, sheet_name='ko_chart')
writer.close()
|
cs |
pandas의 DataFrame으로 song_list를 처리한 다음에 ExcelWriter로 새롭게 만들 엑셀 이름과 시트 이름을 지어준 후 넣어주면 끝!
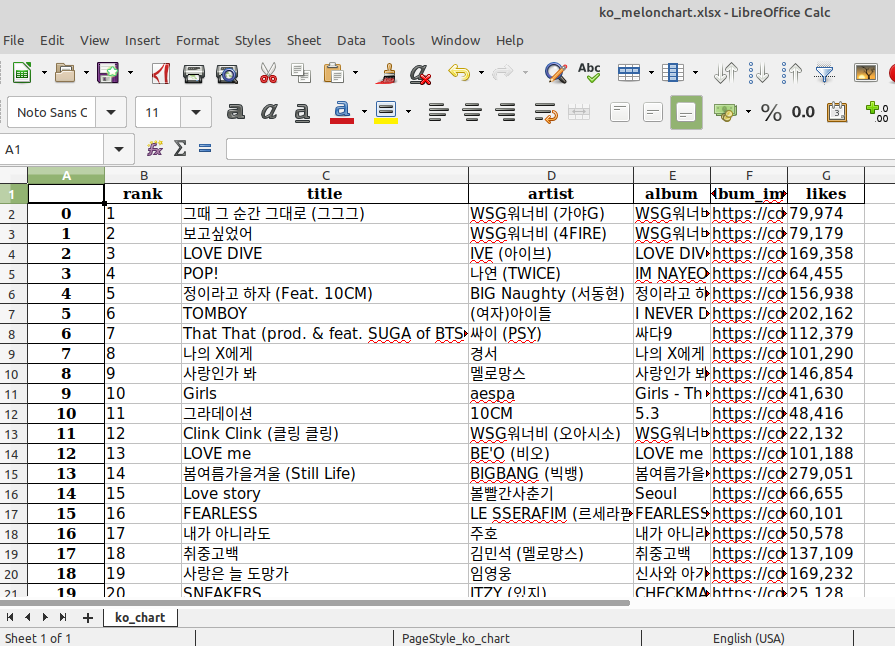
콘솔에는 위와 같이 뜨고 엑셀 파일도 잘 만들어졌다. 만들어진 엑셀 파일은 아래와 같다. (리눅스의 Libreoffice이니 디자인은 감안해주시길...)
전체 코드는 아래와 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
# -*- coding:utf-8 -*-
from selenium import webdriver
from bs4 import BeautifulSoup
import time
import pandas as pd
url = 'https://www.melon.com/chart/day/index.htm'
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(3)
driver.get(url)
time.sleep(1)
# 국내 차트 클릭
ko_chart_xpath = '/html/body/div/div[3]/div/div/div[2]/dl/dd[1]/ul/li[2]/a'
driver.find_element_by_xpath(ko_chart_xpath).click()
time.sleep(2)
# 순위 수집
soup = BeautifulSoup(driver.page_source, 'html.parser')
table = soup.select_one('.service_list_song table tbody')
trs = table.find_all('tr')
song_list = []
for tr in trs:
temp = {}
temp['rank'] = tr.select_one('.rank').text
temp['title'] = tr.select_one('.wrap_song_info').select_one('div.ellipsis.rank01 span a').text
temp['artist'] = tr.select_one('.wrap_song_info').select_one('div.ellipsis.rank02 span a').text
temp['album'] = tr.select_one('td:nth-child(7) > div > div > div > a').text
temp['album_img'] = tr.select_one('td:nth-child(4) > div > a > img').get('src')
temp['likes'] = tr.select_one('.button_etc.like .cnt').text.replace('\n총건수\n', '')
song_list.append(temp)
print(song_list)
# 엑셀에 넣기 위해 처리
ko_chart = pd.DataFrame(song_list)
print(ko_chart.head())
# 저장
writer = pd.ExcelWriter('ko_melonchart.xlsx', engine='openpyxl')
ko_chart.to_excel(writer, sheet_name='ko_chart')
writer.close()
|
cs |
그런데 webdriver를 사용한 이유는 사실 국내종합과 해외종합을 각각 클릭하여 엑셀에 저장하려고 사용한 것이었음. 근데 해외종합 클릭해서 만드는 방법은 사실 반복되는 내용이므로 따로 설명없이 아래 접은 글에 코드를 넣기만 하겠습니다~
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
# -*- coding:utf-8 -*-
from selenium import webdriver
from bs4 import BeautifulSoup
import time
import pandas as pd
url = 'https://www.melon.com/chart/day/index.htm'
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(3)
driver.get(url)
time.sleep(1)
# 국내 차트 클릭
ko_chart_xpath = '/html/body/div/div[3]/div/div/div[2]/dl/dd[1]/ul/li[2]/a'
driver.find_element_by_xpath(ko_chart_xpath).click()
time.sleep(2)
# 순위 수집
soup = BeautifulSoup(driver.page_source, 'html.parser')
table = soup.select_one('.service_list_song table tbody')
trs = table.find_all('tr')
song_list = []
for tr in trs:
temp = {}
temp['rank'] = tr.select_one('.rank').text
temp['title'] = tr.select_one('.wrap_song_info').select_one('div.ellipsis.rank01 span a').text
temp['artist'] = tr.select_one('.wrap_song_info').select_one('div.ellipsis.rank02 span a').text
temp['album'] = tr.select_one('td:nth-child(7) > div > div > div > a').text
temp['album_img'] = tr.select_one('td:nth-child(4) > div > a > img').get('src')
temp['likes'] = tr.select_one('.button_etc.like .cnt').text.replace('\n총건수\n', '')
song_list.append(temp)
print(song_list)
# 엑셀에 넣기 위해 처리
ko_chart = pd.DataFrame(song_list)
print(ko_chart.head())
# 해외 차트 클릭
driver.find_element_by_xpath('/html/body/div/div[3]/div/div/div[2]/dl/dd[1]/ul/li[3]/a').click()
time.sleep(2)
# 순위 수집
soup = BeautifulSoup(driver.page_source, 'html.parser')
table = soup.select_one('.service_list_song table tbody')
trs = table.find_all('tr')
song_list = []
for tr in trs:
temp = {}
temp['rank'] = tr.select_one('.rank').text
temp['title'] = tr.select_one('.wrap_song_info').select_one('div.ellipsis.rank01 span a').text
temp['artist'] = tr.select_one('.wrap_song_info').select_one('div.ellipsis.rank02 span a').text
temp['album'] = tr.select_one('td:nth-child(7) > div > div > div > a').text
temp['album_img'] = tr.select_one('td:nth-child(4) > div > a > img').get('src')
temp['likes'] = tr.select_one('.button_etc.like .cnt').text.replace('\n총건수\n', '')
song_list.append(temp)
uni_chart = pd.DataFrame(song_list)
# 저장
writer = pd.ExcelWriter('melonchart.xlsx', engine='openpyxl')
ko_chart.to_excel(writer, sheet_name='ko_chart')
uni_chart.to_excel(writer, sheet_name='uni_chart')
writer.close()
|
cs |
진짜 끝!
'파이썬' 카테고리의 다른 글
| 파이썬 프로젝트(3) : flask로 파이썬에서 Spring으로 데이터 보내기 (0) | 2022.11.23 |
|---|---|
| 파이썬 프로젝트(2) : KoalaNLP으로 키워드 추출해내기 (0) | 2022.09.23 |
| 파이썬 프로젝트(1) : 펀딩 추천 시스템 - userbase, contentbase (0) | 2022.09.14 |
| 파이썬 : 입력한 숫자만큼 로또 번호 출력하기 (0) | 2022.07.22 |



댓글